
한사이클에 안하고 여러 스텝을 두고 여러 스텝을 한사이클에 실행
서로다른 instruction이 서로 다른 cycle 수에 실행된다
-
1.instruction을 memory로부터 읽어온다(instruction fetch)
-
2.instruction이 뭔가를 살펴보고 register 두개를 읽는다(instruction decode/register fetch)
-
3.ALU연산(ALU Operation)
-
4.Register에 가서 target register update
load라면
유사하지만
3.에서 address를 계산하고
4.에서 memory를 읽고
5.register에 target register udpate
만약 4,5를 합쳐서 한번에 하면 cycle time이 커져서 모든것이 피해를 받는다

multicycle에선 resource를 각 사이클마다 다른용도로 사용
memory unit도 instruction memory data memory 따로 있지 않고
single memory로 존재한다
adder또한 마찬가지로 single ALU로 존재
하지만 multi cycle에선 해당 cycle 말고 다음 cycle까지도 필요한 것들을 저장할 temprorary register 등장
그래서 시간이 오래걸리는
-
memory access
-
register file access
-
ALU operation
이것들은 한번에 하나만 할수있다 at most
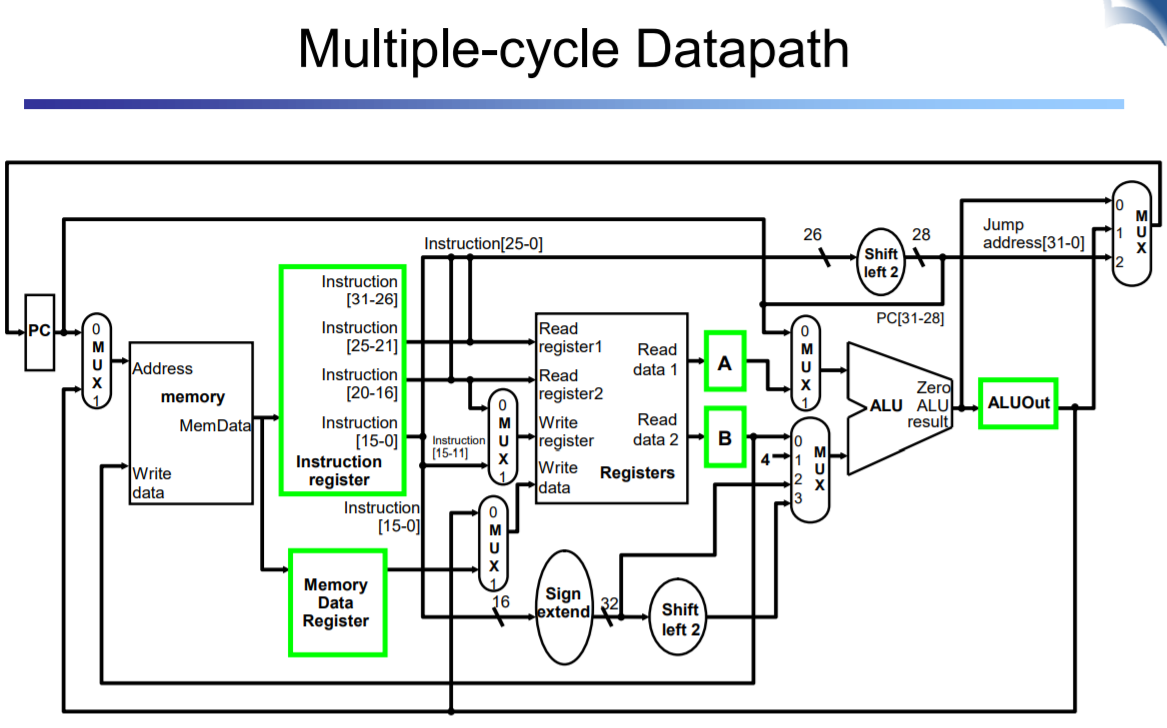
녹색이 temporary register
ALU memory 통합

1,2에서는 동일한 기능 수행
R type은 후에 2 cycle 수행
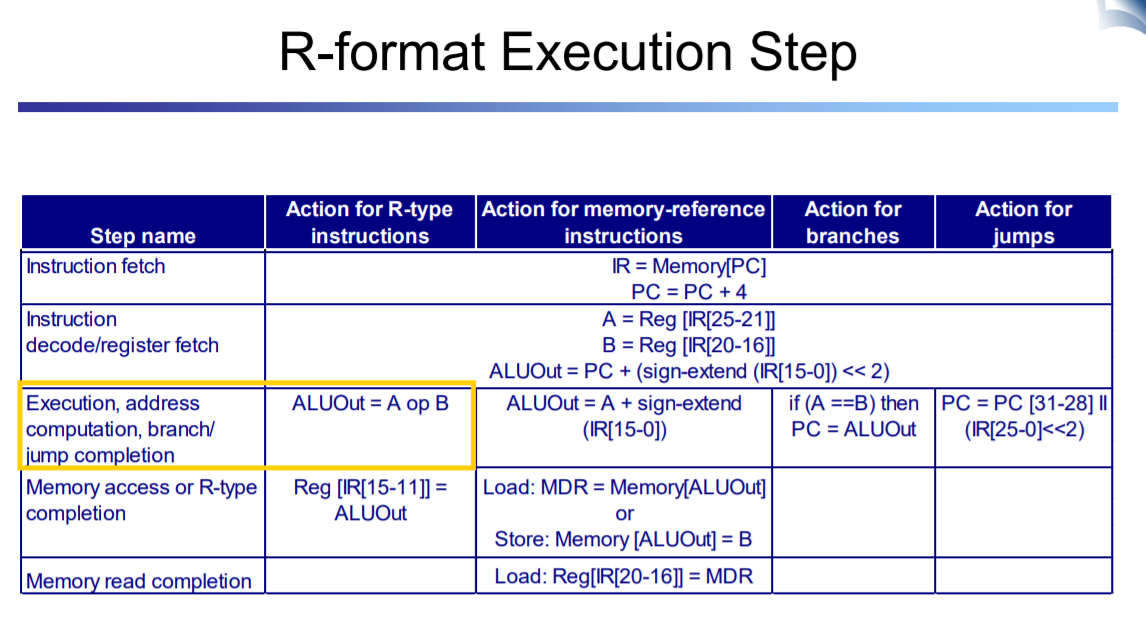
action for memory-reference instructions
즉 load or store의 경우 공통적으로 3번째에서 주소를 계산하고
load면 4에서 메모리에서 읽고 5번째에서 target register에 적는다
store라면 3에서 주소를 계산하고 4에서 그 주소에 register 값 하나를 적는다
branch는 추가로 하나만 필요한데
A 와 B가 같은 경우엔 PC의 주소를 target address로 update 해준다
jump도 마찬가지이다

PC에 해당하는 걸 memory에서 가져온다
PC를 4더한다
이걸 그림에서 보게되면

PC값을 메모리에 집어넣고 그럼 instruction이 나온다
그리고 pC에 상수 4를 더해서 PC로 들어간다
그러면 1번째 cycle이 끝나면 instruction 32bit가 memory 뒤에서 기다리고 있는다
첫번쨰 클락의 falling edge가 발생하면 instruction 32bit가 instruction register에 들어오고
PC의 값이 PC + 4가 된다
하지만 branch jump에선 PC + 4가 굳이 필요없지만 한다
이걸 speculation이라고 한다 실행까지 더하면 speculative execution이라고 한다


register 해당 위치에 있는 두 값을 읽어서 temporary register에다가 집어넣는다
그리고 branch target address를 계산한다
R format 3번쨰 cycle에선 두 register 값에 ALU operation을 가한다
4번쨰에선 ALUout값을 target register에다가 적으면 된다

instruction register에서 source register 두개를 읽어서
그 register 값을 A B temporary register에 적어두고
PC +4의 값하고 instruction의 16비트를 sign extend해서 * 4해서 두개 더하면 branch target address가 된다
두번째 사이클이 끌날떄는 레지스터 두개값이 AB 앞에서 기다리고
branch target address 가 ALU 뒤에서 기다린다
falling edge가 되면 AB에 들어가고 branch target address는 ALUout에 들어간다
3번째 cycle부터는 각자 갈길 가는데
R type의 경우 두개 A B를 어떤 r type인지에 따라 operation하면 된다

ALU에서 해당 operation을 계산해서
ALUout에 넣고


마지막 cycle에서는 target address 적힌 값 write data로 보내주고
target register를 instruction으로 부터 읽어서 taget register의 번호로 update한다
4번쨰 cycle이 끝날때에는 write register와 write data 앞에서 기다리고 있는다
클락의 falling edge때 target register의 값이 변한다

A에는 이미 있고 instruction 16 bit을 32bit으로 sign extend 한것을 ALU에서 더해서
ALUout에 저장

3번쨰 cycle의 끝쯤 되면은 ALU 뒤에서 기다리고 있다가 falling edge때 ALUout으로 들어간다

Load의 경우 ALUout에 해당하는 주소에서 메모리에서 읽어서 MDR이라는 또다른 temporary register에 저장

cycle이 끝날때 memory data register 앞에서 기다리고 있다가
falling edge때 들어간다

5번째는 target register에 각각 적는거다

5번째 사이클에 write register write data 앞에서 기다린다

store의 경우
B에 있는 값을 메모리에 쓴다

B의 값을 memory의 writedata로 보내고 주소는 ALUout에서 온다

branch의 경우 이미 branch target address를 계산했기 때문에
두 register의 값이 같다면 ALUout에 해당하는 address로 PC를 이동하고
그렇지 않다면 아까 수행한 PC +4 로 간다

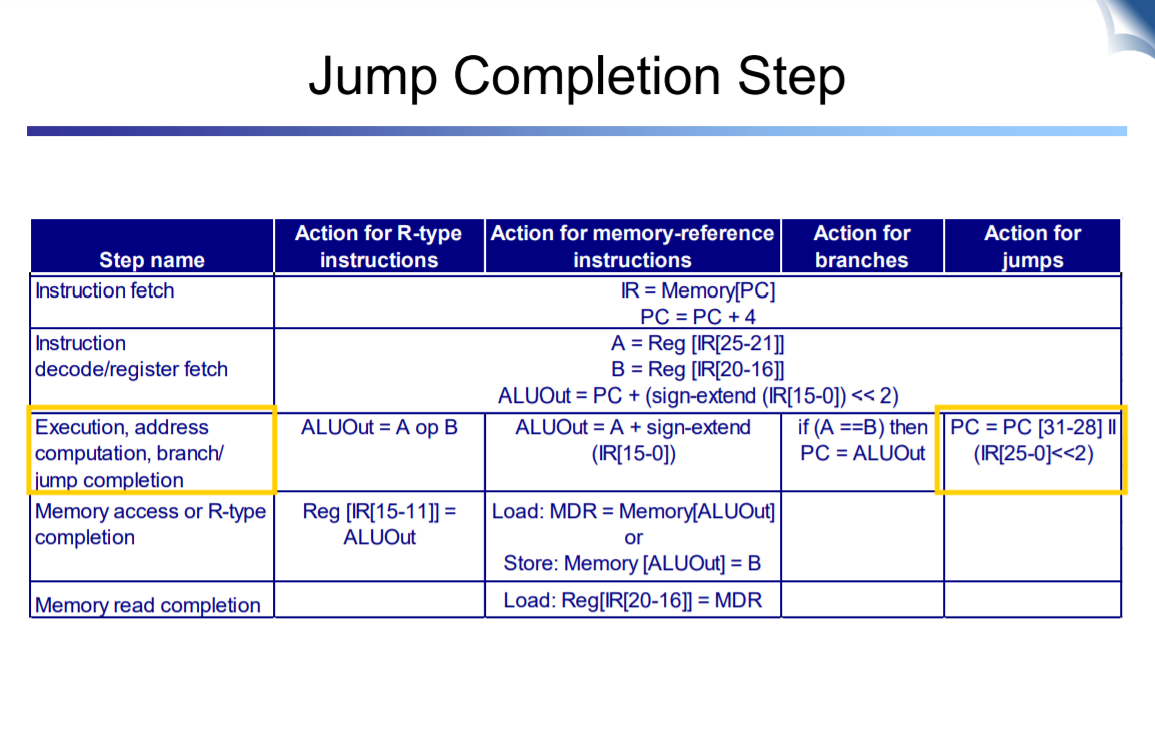
jump의 경우 PC에서 4bit 떼어오고 뒤에 00 붙힌다 그다음 concat해서 PC로 보낸다


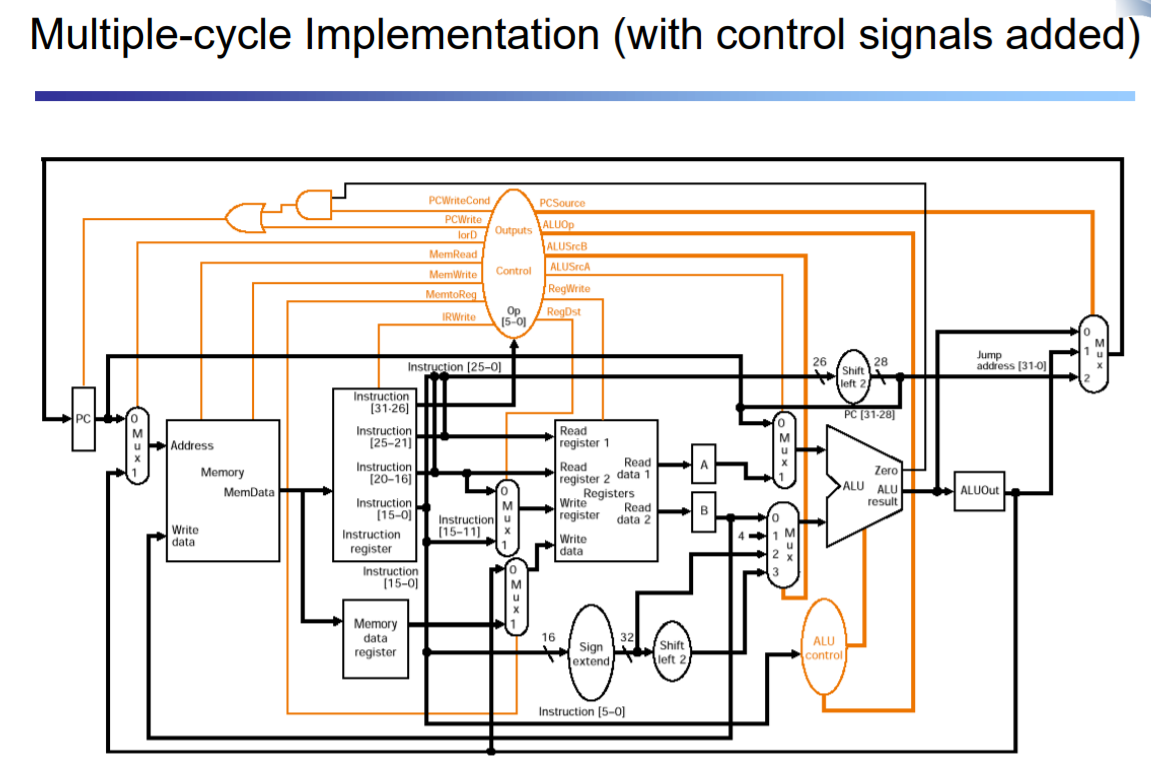
다양한 control signal 필요
어떤 cycle에 있는지 파악 필요하다
그 과정에서 필요한게 finite state machine이다

output이 control signal이 될것이다
next state function이 다음의 어떤 state로 갈지 정한다
무어와 밀리가 있지만
우리는 state만 알면 되서 무어이다

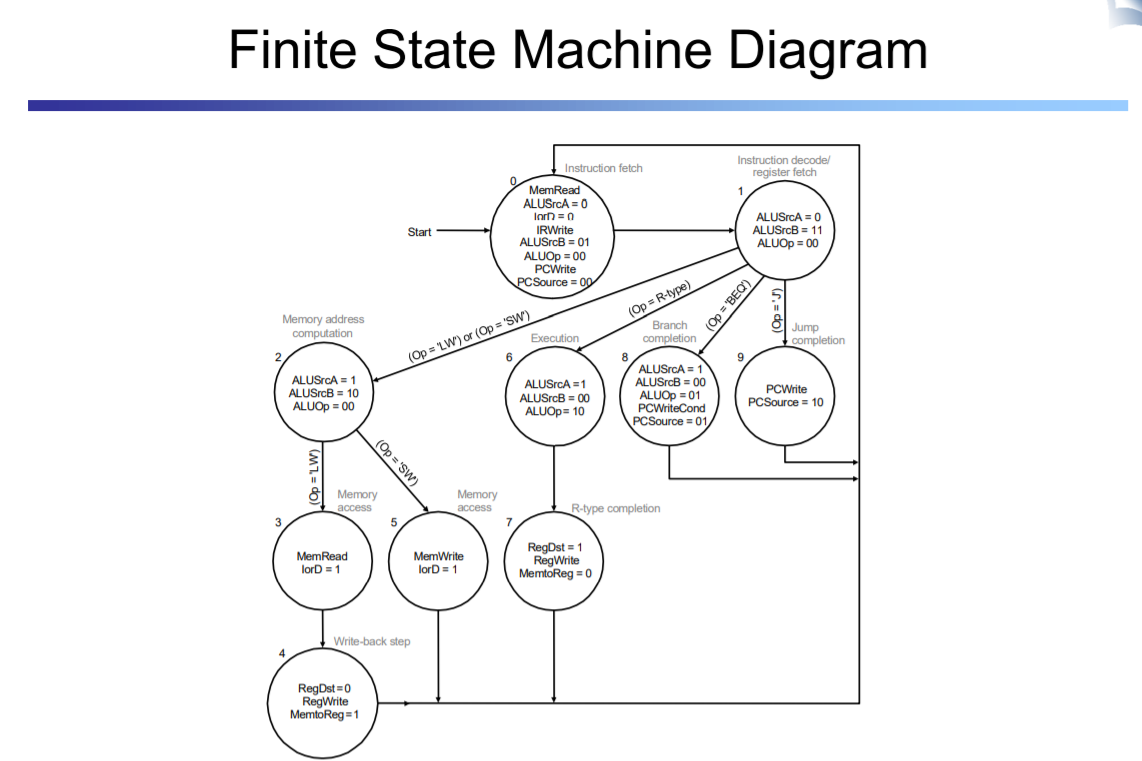
해당 state에 따라서 control signal을 다 만들어낼수 있다

state register를 통해서 10개중 어떤 state인지 알고 instruction opcode를 통해서
어떤 instruction인지 파악하여 control signal과
다음 state는 뭔지를 파악할수 있다

PLA의 핵심은 모든 logic function은 sum of product로 이루어진다

exception은 지금 실행되고 있는 instruction이 유발한 exceptional한 event
interrupt는 지금 실행되고 있는 것과는 상관없이 외부에서 asyncronized하게 들어온 exceptional하게 들어온 event
exception이건 interrupt건 operating system에게 control이 간다
나중에 실행되고 있는 프로그램으로 돌아가기 위해
EPC(Exception program counter)에 현재 PC를 저장한다
어떤 이유로 발생하였는가에 대해서 CAUSE라는 register에 저장
그러고 나서 operating system에서 exception 또는 interrupt를 처리하는 곳으로 이동
EPC에 있는 값을 PC로 돌아가서 원래 돌던 user program으로 돌아감
EPC와 CAUSE는 PC와 마찬가지로 Machine state에 포함된다
이유는 operating system이 만지기 위해서다


































{kind=link}